






Tuesday, February 16
TI Blaze. Screw the iPad. This is the future.
On the one hand, it's a huge clunky thing.
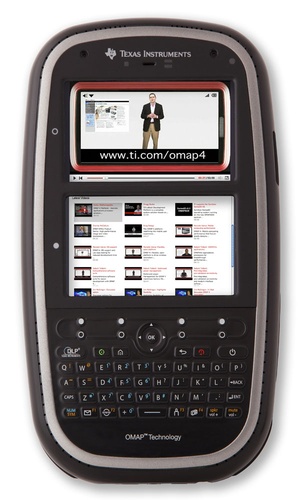
On the other hand, it's a development platform, not a consumer device; it has two 800x480 touchscreens, HDMI out, and a built-in DLP projector; it has two five-megapixel cameras at front and a twelve-megapixel camera at rear; a dual-core 1.2GHz Arm Cortex A9 (superscalar out-of-order SMP); accelerometer, compass, ambient light, proximity, barometric and temperature sensors; Wifi, Bluetooth, and GPS; and easy and open access to all the electronics, networking, and software.
Tech's slate (from the Accountancy story further down) isn't that much more advanced than this beastie.
Posted by: Pixy Misa at
04:04 AM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 108 words, total size 1 kb.
EA have just earned themselves brownie points with millions of gamers by re-releasing three of the older Command and Conquer games - Red Alert, Tiberian Dawn, and Tiberian Sun - free.
Get downloading!
Posted by: Pixy Misa at
12:26 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 36 words, total size 1 kb.
Sunday, February 14
I have a working base storage class for Pita. Unfortunately, most of my weekend was eaten up by my day job and other miscellanea, but it does work.
I'll post the full code later in the week once I have a derived class or two that does something more useful, in the meantime, here's the test code to give you an example of how it's used:
def oodle_test():
# Create a base view
pets = Oodle()
# Create some pets
log('Creating pets')
# Create a dog, and save it
pet = pets.new()
pet.animal = 'dog'
pet.sound = 'woof'
pet.save()
log('Dog saved, %s pets' % pets.count(),1)
# Create a cat from a dict, and save it
pet = pets.new({'animal': 'cat', 'sound': 'meow'})
pet.save()
log('Cat saved, %s pets' % pets.count(),1)
# Append an aardvark
pet = pets.append({'animal': 'aardvark', 'sound': 'snorf'})
log('Aardvark appended, %s pets' % pets.count(),1)
# Append a hippopotamus too
pet = pets.append(animal = 'hippopotamus', sound = 'hrooonk')
log('Hippopotamus appended, %s pets' % pets.count(),1)
# What pets do I have?
log('Selecting all pets')
for pet in pets.select():
log('My %s says %s' % (pet.animal, pet.sound),1)
# Select and find on fields
log('Selecting specific pets')
# What does my dog say?
for pet in pets.select(animal = 'dog'):
log('Selected my %s; it says %s' % (pet.animal, pet.sound),1)
# Can I find my cat?
pet = pets.find(animal = 'cat')
log('Found my %s; it says %s' % (pet.animal, pet.sound),1)
return pets.count() == 4The results of the test?
Creating pets
Dog saved, 1 pets
Cat saved, 2 pets
Aardvark appended, 3 pets
Hippopotamus appended, 4 pets
Selecting all pets
My dog says woof
My cat says meow
My aardvark says snorf
My hippopotamus says hrooonk
Selecting specific pets
Selected my dog; it says woof
Found my cat; it says meow
Oodle OKUpdate: 0.03! I deleted my pet hippopotamus!
Update: 0.04! The idiom
for pet in pets now works. You can't slice it or select within it yet.
Posted by: Pixy Misa at
11:34 PM
| Comments (8)
| Add Comment
| Trackbacks (Suck)
Post contains 356 words, total size 3 kb.
Come to think of it, I need to redo them to insert Jy and Pi. So there may be another colour shift coming.
Posted by: Pixy Misa at
08:49 PM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 24 words, total size 1 kb.
Idea popped into my head for a story set in the Mina Smith universe. Mina's a customs agent, but this time our protagonist is an accountant. As much an accountant as Mina is a customs agent, anyway.
Just a snippet that I'll likely never finish, but anyway...
more...
Posted by: Pixy Misa at
06:38 AM
| Comments (4)
| Add Comment
| Trackbacks (Suck)
Post contains 1937 words, total size 12 kb.
I can't configure a server on your site with more than 4GB of RAM or SATA drives bigger than 250GB. Last time I checked it was not 2002, so could you please FIX IT?
Posted by: Pixy Misa at
02:15 AM
| Comments (1)
| Add Comment
| Trackbacks (Suck)
Post contains 37 words, total size 1 kb.
Well, sort of. Kind of sort of.*
Okay, quick, tell me what language this is (without Googling the source code):
print "Eratosthenes' Sieve, in some funny language"
function print_sieve (limit):
local sieve, j = { }, 2
while j<limit:
while sieve[j]:
j=j+1
print(j)
for k = j*j, limit, j:
sieve[k] = true
j=j+1
print_sieve(100)Hint the second: It's the same language as this (believe it or not):
map = |f,x| x ? %{ hd=f(x.hd), tl=map(f,x.tl) }
filter = |p,x| x ? p(x.hd) ? %{ hd=x.hd, tl=filter(p, x.tl) }, filter(p, x.tl)
take = |n,s| n<=0 ? { }, { s.hd, unpack(take(n-1, s.tl)) }
ints = %{ hd=1; tl=map (|x| x+1, ints) }
f = |seq| %{ hd=seq.hd; tl=f(filter (|x| x%seq.hd~=0, seq.tl)) }
primes = f (ints.tl)
table.print(take (100, primes))Hint the third: You'll be able to script your mee.nu blog like this soon.
* Good language designers borrow. Great language designers swipe someone else's metaprogramming project.
Posted by: Pixy Misa at
01:48 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 199 words, total size 2 kb.
Saturday, February 13
I was looking at YAML as a serialisation option for Pita (it's already supported for exporting data in the development version of Minx).
So I ran some benchmarks.
It's sloooooooooooooooooooow.
Here we are, encoding and decoding a 2k record:
[andrew@eineus ~]$ python jsonbench.py
10000 iterations on 1973 bytes
Python
json: 10000 encodes+decodes in 4.9 seconds, 2055.8 per second
simplejson: 10000 encodes+decodes in 0.5 seconds, 20686.2 per second
pickle: 10000 encodes+decodes in 4.3 seconds, 2338.0 per second
cPickle: 10000 encodes+decodes in 0.6 seconds, 17297.6 per second
yaml: 10000 encodes+decodes in 213.4 seconds, 46.9 per second
json is Python's built-in JSON library, which is written in Python and thus somewhat sluggish. simplejson is the same JSON library with an optional C implementation. Essentially the same applies for pickle vs. cPickle.
yaml is PyYAML, which includes a C implemenation if you have LibYAML installed. Which I do, but I can't seem to get the C implemenation to run... Unless that's it, which would be pretty sad.
On the one hand, simplejson is the fastest of these options, which is good because it's also the most widely supported format and the easiest to parse.
One the other hand, 20,000 records per second is not all that much.
Posted by: Pixy Misa at
04:37 PM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 205 words, total size 1 kb.
Announcing Jsyn, the JSON syndication format for blogs and everything else.
Specification for version sqrt(-1):
1. Put a bunch of stuff in a data structure.
2. JSON-encode it.
3. Make it available somehow.
...
What, you need more of a spec? But I've registered a domain and everything!
Seriously, freedom from so-called "simple" syndication, coming soon! Part of the Pita* project.
Update: Spec version -1:
A Jsyn feed object will have precisely three first level sub-elements:
1. A
feed element, an object containing the feed properties (required).2. A
schema element, an object containing advisory schema information (optional).3. A
items element, an array of objects representing the data items (required, but may be empty).Example:
{"feed": {"source": "http://ai.mee.nu/feed.jsyn"},
"schema": {"source": "http://jsyn.net/schemas/blog.jsyn", "version": 1.0},
"items": []}
A client may use a local copy of the schema so long as the version matches that specified in the
schema object. The server must increment the version when updating the schema. The server may revert to an older schema with a lower version number; the client must not continue to use the local copy of the schema in this case.* Which is part of the Minx project**, which is part of the make-Pixy-rich-or-drive-him-insane-either-is-fine project.
** I've subdivided Minx into three parts, like Gaul, only with less garlic: Minx, the bliki; Meta, the template, formatting, and scripting engine; and Pita, the database engine/abstraction layer. In addition, there's Miko, the planned desktop client.
Posted by: Pixy Misa at
01:17 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 240 words, total size 2 kb.
Now where the heck was I, before being buried under an avalanche of poorly-considered Atom feeds and Chinese replica watch spam?
Ah, right.
We can't do a full Progress-style
where clause in Python, unfortunately. Or not without more trickery than I intend to apply; someone did make a working goto - never mind that, a working comefrom - but I'm not inclined to go to that sort of length.So. I want the first 20 posts in a given folder of a given blog, sorted by date order (descending, of course). Pythonically. No SQL. Let's see:
db = Pita.Connect(host, user, pass, database)
posts = db.views.postsfor post in posts(folder=f,order='date-',limit=20):
...authors = db.views.authors
a = authors.find(name='Pixy Misa')
for post in posts(author=a.id, tag='databases',order='score-',limit=20):
...for post in posts(author.name = 'Pixy Misa')for author in authors(country = 'Australia')for author in authors('Andorra' < country < 'Azerbaijan')Now, the design of Pita is that it's primarly a document database with advisory schemas. It's not schemaless like many or the key-value stores, and it's not fixed-schema like most traditional relational databases. Each view has a schema, which specifies what fields should be there, and if they are, what type they should be. Fields can be missing, in which case the schema may specify a default value. And you can stick in whatever additional data you want, so long as the schema doesn't specifically conflict with that.
What this means is that we can know that
country is a string, and if we do an equality comparison between a string and a list, we mean that we want to know if the string is in the list. So we can also do this:for author in authors(country = ['Australia', 'New Zealand', 'Canada'])By returning a generator or iterator, we can efficiently replace this:
for post in posts(blog=b,tag='databases',order='score-',limit=20)for post in posts(blog=b,tag='databases',order='score-')[:20]But what about range searches? There's no obvious Pythonic syntax for this, at least, not one that works. Here are a few possiblities:
for house in houses(price = '<100000'):
...
for house in houses(price = ['>50000','<100000']):
...
We could have an explicit range function:
for house in houses.price.range(50000,100000):
...for house in houses.price.range(50000,100000,suburb='Wondabyne'):
...Since we're building a generator, it should be possible to do this LINQish trick:
for house in houses(suburb='Wondabyne').price.range(50000,100000):
...We should be able to keep doing that sort of thing, until we get something like:
for house in houses.suburb('Wondabyne').bedrooms.range(3,5).bathrooms.min(2).price.max(150000).order('price+'):
...
Posted by: Pixy Misa at
03:13 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 701 words, total size 5 kb.
56 queries taking 0.2645 seconds, 402 records returned.
Powered by Minx 1.1.6c-pink.


