






Back in a moment.
Thank you Santa.
Sunday, February 28
The closing credits of Hanamaru Kindergarten might win the nod for the best anime of the season.
Posted by: Pixy Misa at
11:53 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 20 words, total size 1 kb.
Saturday, February 27
Also crazed starving weasels.
Posted by: Pixy Misa at
04:24 PM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 7 words, total size 1 kb.
Friday, February 26
Now with added mouseoverness.
Posted by: Pixy Misa at
02:00 AM
| Comments (5)
| Add Comment
| Trackbacks (Suck)
Post contains 7 words, total size 2 kb.
Thursday, February 25

The Grand Unified Minx Theory
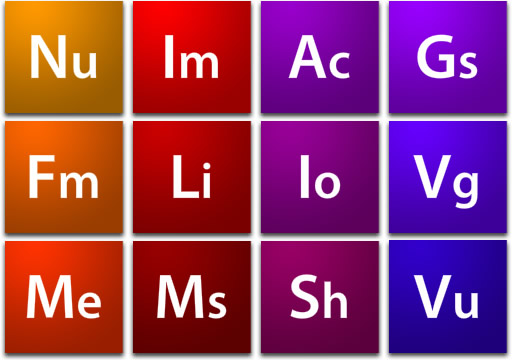
The mee.nu User Domains

The Minx Components
Posted by: Pixy Misa at
05:40 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 13 words, total size 1 kb.
Wednesday, February 24
Naturally I had to try this...
100%

50%

Oops!
Now, that's a deliberately constructed corner case, but there is a problem there.
Posted by: Pixy Misa at
12:40 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 24 words, total size 1 kb.
Monday, February 22
Posted by: Pixy Misa at
05:44 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 2 words, total size 1 kb.
Sunday, February 21
I'm in here:
(Click for full screenshot. Thanks go to Steam and GOG's insane holiday sales.)
Actually, I'm not; I'm doing work for my day job, making some progress with Pita, reorganising Meta, and have finally come to a design decision on Miko (all parts of the Minx project for those who haven't been paying attention), redoing the documentation in Sphinx - which will itself be supported in an upcoming version of Meta - and planning for this year's server upgrade.* I did play a bit of Dragon Age over the holidays, but games are taking a back seat for a while.** Despite the fact that I have 224 of them currently installed.
* If things go right we'll be moving from a lowly 8-processor (16-thread) 2.26GHz server with 24GB of RAM to a spiffy new 12-processor (24-thread) 2.66GHz server with 48GB of RAM. That's at least partly to prepare for the move to Pita, which loves to store stuff in memory. Because I can just copy the OpenVZ virtual machines across, the move should be quick and painless.
** Apart from Billy vs. SNAKEMAN!

Posted by: Pixy Misa at
02:16 PM
| Comments (6)
| Add Comment
| Trackbacks (Suck)
Post contains 188 words, total size 1 kb.
Hidamari Sketch continues to exist in its own little universe, and all is right with the world.
Posted by: Pixy Misa at
04:12 AM
| Comments (3)
| Add Comment
| Trackbacks (Suck)
Post contains 18 words, total size 1 kb.
Saturday, February 20
In SQL* you say
select sum(sales) from accounts where state="NY". In Pita, the way to do this is:results = accounts.aggregate(state='NY')**results.sales.sum. Since the table scan is typically slower than any calculations you're likely to be doing, this seems a reasonable approach.In addition, I've added a
results = accounts.stats()I'm working on two more functions now,
group and break, though I may need to come up with another name for the latter because break is a Python keyword. This:for result in accounts.group('state', country='US'): ...for result in accounts.break('state', country='US'):
...As long as I don't come down with kurtosis...
Update: Kang and jag. Or rather, agg and tab. For aggregate and tabulate.
for line in accounts.aggregate('state', country='US'): ...for line in accounts.tabulate('state', country='US'):
...* Boo, hiss!
** Or indeed
results = *** Which should come out the same as the average; just one I'm calculating myself and the other I'm pulling out of a stats module.
Posted by: Pixy Misa at
03:14 AM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 316 words, total size 3 kb.
Tuesday, February 16

Okay, yeah, they needed that sharpening filter. That's Minx's built-in upscaling. Quality is not so hot, as it turns out. I'll check on what filter it's using; normally it's only used for downscaling, which works great:

Posted by: Pixy Misa at
11:35 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 39 words, total size 1 kb.
26 queries taking 0.0421 seconds, 66 records returned.
Powered by Minx 1.1.6c-pink.


