






Oh, lovely, you're a cheery one aren't you?
Friday, February 26
Now with added mouseoverness.
Posted by: Pixy Misa at
02:00 AM
| Comments (5)
| Add Comment
| Trackbacks (Suck)
Post contains 7 words, total size 2 kb.
Thursday, February 25

The Grand Unified Minx Theory
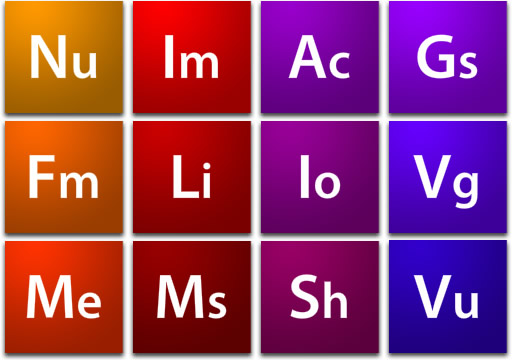
The mee.nu User Domains

The Minx Components
Posted by: Pixy Misa at
05:40 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 13 words, total size 1 kb.
Wednesday, February 24
Naturally I had to try this...
100%

50%

Oops!
Now, that's a deliberately constructed corner case, but there is a problem there.
Posted by: Pixy Misa at
12:40 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 24 words, total size 1 kb.
Monday, February 22
Posted by: Pixy Misa at
05:44 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 2 words, total size 1 kb.
Sunday, February 21
I'm in here:
(Click for full screenshot. Thanks go to Steam and GOG's insane holiday sales.)
Actually, I'm not; I'm doing work for my day job, making some progress with Pita, reorganising Meta, and have finally come to a design decision on Miko (all parts of the Minx project for those who haven't been paying attention), redoing the documentation in Sphinx - which will itself be supported in an upcoming version of Meta - and planning for this year's server upgrade.* I did play a bit of Dragon Age over the holidays, but games are taking a back seat for a while.** Despite the fact that I have 224 of them currently installed.
* If things go right we'll be moving from a lowly 8-processor (16-thread) 2.26GHz server with 24GB of RAM to a spiffy new 12-processor (24-thread) 2.66GHz server with 48GB of RAM. That's at least partly to prepare for the move to Pita, which loves to store stuff in memory. Because I can just copy the OpenVZ virtual machines across, the move should be quick and painless.
** Apart from Billy vs. SNAKEMAN!

Posted by: Pixy Misa at
02:16 PM
| Comments (6)
| Add Comment
| Trackbacks (Suck)
Post contains 188 words, total size 1 kb.
Saturday, February 20
In SQL* you say
select sum(sales) from accounts where state="NY". In Pita, the way to do this is:results = accounts.aggregate(state='NY')**results.sales.sum. Since the table scan is typically slower than any calculations you're likely to be doing, this seems a reasonable approach.In addition, I've added a
results = accounts.stats()I'm working on two more functions now,
group and break, though I may need to come up with another name for the latter because break is a Python keyword. This:for result in accounts.group('state', country='US'): ...for result in accounts.break('state', country='US'):
...As long as I don't come down with kurtosis...
Update: Kang and jag. Or rather, agg and tab. For aggregate and tabulate.
for line in accounts.aggregate('state', country='US'): ...for line in accounts.tabulate('state', country='US'):
...* Boo, hiss!
** Or indeed
results = *** Which should come out the same as the average; just one I'm calculating myself and the other I'm pulling out of a stats module.
Posted by: Pixy Misa at
03:14 AM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 316 words, total size 3 kb.
Tuesday, February 16

Okay, yeah, they needed that sharpening filter. That's Minx's built-in upscaling. Quality is not so hot, as it turns out. I'll check on what filter it's using; normally it's only used for downscaling, which works great:

Posted by: Pixy Misa at
11:35 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 39 words, total size 1 kb.
Sunday, February 14
I have a working base storage class for Pita. Unfortunately, most of my weekend was eaten up by my day job and other miscellanea, but it does work.
I'll post the full code later in the week once I have a derived class or two that does something more useful, in the meantime, here's the test code to give you an example of how it's used:
def oodle_test():
# Create a base view
pets = Oodle()
# Create some pets
log('Creating pets')
# Create a dog, and save it
pet = pets.new()
pet.animal = 'dog'
pet.sound = 'woof'
pet.save()
log('Dog saved, %s pets' % pets.count(),1)
# Create a cat from a dict, and save it
pet = pets.new({'animal': 'cat', 'sound': 'meow'})
pet.save()
log('Cat saved, %s pets' % pets.count(),1)
# Append an aardvark
pet = pets.append({'animal': 'aardvark', 'sound': 'snorf'})
log('Aardvark appended, %s pets' % pets.count(),1)
# Append a hippopotamus too
pet = pets.append(animal = 'hippopotamus', sound = 'hrooonk')
log('Hippopotamus appended, %s pets' % pets.count(),1)
# What pets do I have?
log('Selecting all pets')
for pet in pets.select():
log('My %s says %s' % (pet.animal, pet.sound),1)
# Select and find on fields
log('Selecting specific pets')
# What does my dog say?
for pet in pets.select(animal = 'dog'):
log('Selected my %s; it says %s' % (pet.animal, pet.sound),1)
# Can I find my cat?
pet = pets.find(animal = 'cat')
log('Found my %s; it says %s' % (pet.animal, pet.sound),1)
return pets.count() == 4The results of the test?
Creating pets
Dog saved, 1 pets
Cat saved, 2 pets
Aardvark appended, 3 pets
Hippopotamus appended, 4 pets
Selecting all pets
My dog says woof
My cat says meow
My aardvark says snorf
My hippopotamus says hrooonk
Selecting specific pets
Selected my dog; it says woof
Found my cat; it says meow
Oodle OKUpdate: 0.03! I deleted my pet hippopotamus!
Update: 0.04! The idiom
for pet in pets now works. You can't slice it or select within it yet.
Posted by: Pixy Misa at
11:34 PM
| Comments (8)
| Add Comment
| Trackbacks (Suck)
Post contains 356 words, total size 3 kb.
Well, sort of. Kind of sort of.*
Okay, quick, tell me what language this is (without Googling the source code):
print "Eratosthenes' Sieve, in some funny language"
function print_sieve (limit):
local sieve, j = { }, 2
while j<limit:
while sieve[j]:
j=j+1
print(j)
for k = j*j, limit, j:
sieve[k] = true
j=j+1
print_sieve(100)Hint the second: It's the same language as this (believe it or not):
map = |f,x| x ? %{ hd=f(x.hd), tl=map(f,x.tl) }
filter = |p,x| x ? p(x.hd) ? %{ hd=x.hd, tl=filter(p, x.tl) }, filter(p, x.tl)
take = |n,s| n<=0 ? { }, { s.hd, unpack(take(n-1, s.tl)) }
ints = %{ hd=1; tl=map (|x| x+1, ints) }
f = |seq| %{ hd=seq.hd; tl=f(filter (|x| x%seq.hd~=0, seq.tl)) }
primes = f (ints.tl)
table.print(take (100, primes))Hint the third: You'll be able to script your mee.nu blog like this soon.
* Good language designers borrow. Great language designers swipe someone else's metaprogramming project.
Posted by: Pixy Misa at
01:48 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 199 words, total size 2 kb.
Saturday, February 13
I was looking at YAML as a serialisation option for Pita (it's already supported for exporting data in the development version of Minx).
So I ran some benchmarks.
It's sloooooooooooooooooooow.
Here we are, encoding and decoding a 2k record:
[andrew@eineus ~]$ python jsonbench.py
10000 iterations on 1973 bytes
Python
json: 10000 encodes+decodes in 4.9 seconds, 2055.8 per second
simplejson: 10000 encodes+decodes in 0.5 seconds, 20686.2 per second
pickle: 10000 encodes+decodes in 4.3 seconds, 2338.0 per second
cPickle: 10000 encodes+decodes in 0.6 seconds, 17297.6 per second
yaml: 10000 encodes+decodes in 213.4 seconds, 46.9 per second
json is Python's built-in JSON library, which is written in Python and thus somewhat sluggish. simplejson is the same JSON library with an optional C implementation. Essentially the same applies for pickle vs. cPickle.
yaml is PyYAML, which includes a C implemenation if you have LibYAML installed. Which I do, but I can't seem to get the C implemenation to run... Unless that's it, which would be pretty sad.
On the one hand, simplejson is the fastest of these options, which is good because it's also the most widely supported format and the easiest to parse.
One the other hand, 20,000 records per second is not all that much.
Posted by: Pixy Misa at
04:37 PM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 205 words, total size 1 kb.
55 queries taking 0.2201 seconds, 391 records returned.
Powered by Minx 1.1.6c-pink.


