






Twelve years!
You hit me with a cricket bat!
Ha! Twelve years!
Tuesday, February 27
I had a couple of must-do items before I started the Minx beta tests:
- Switch from the built-in CherryPy session storage to a MySQL back-end
- Not run the darn thing as root
They should be simple.
In the case of the CherryPy session storage, the CherryPy docs are (a) incomplete and apparently (b) wrong. It looks like the only way to plug in your own session storage module is to directly hack the CherryPy source. It's not supposed to be that way, but if I have to, I can do that.
In the case of not running as root, well, there's a couple of ways to do it. The main problem is that Minx has to listen on port 80, and only root can listen on port 80, and running as root is a Bad Idea.
One way around this is to change the userid after startup, when the port is already established. I'm not sure why, but this causes Minx to lock up after the first request. Another is to use Apache and mod_proxy, but there's no way in hell I'm going to all that trouble. I'm doing all this in large part to get away from frigging Apache. Another way is to use a reverse proxy like Pound. I tried that, and it kind of worked. (It looked like it was broken, but that was actually due to the lockup problem I mention above. I expect if I try it again it will work flawlessly... Yep. Okay, so that at least isn't time wasted; Pound could well prove useful as we roll out more servers.)
Another way is to use iptables redirects. This is the simplest and most reliable way, and doesn't bloody work on my system. It works fine on my other Linux box, but not on the Minx test box, and not on the Minx production box. Why, I don't know. But iptables dnat does work, as it turns out, two hours of intense frustration later. I'm guessing that the redirect was redirecting to the wrong IP - localhost, or something. Minx binds itself to a specific IP so that I can run multiple instances per server, so that I can balance across the CPUs. (Python is multi-threaded, but only one thread can be executing Python code at any time. OS calls are multi-threaded, but the data crunching isn't. So to get the most out of Minx on our multi-processor servers, I'm using multiple instances of Minx and round-robin DNS.)
Uh, anyway. Currently working in a secured environment with file-based sessions. That will do for the beta test, and allows me to check off item 0 on my bug list. That leaves 22 items, plus one marked "bah".
Update: Bandwidth logging, which required using CherryPy callbacks, something I hadn't used before, worked second go. Much better.
Posted by: Pixy Misa at
07:15 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 479 words, total size 3 kb.
Monday, February 26
Not so much reorganising the code to better fit the design changes, as reorganising the theoretical design to match the actual design.
We now have four types of site... And thirty-sixeight types of folder. (Standard types. You can create your own arbitrary folder types, but they don't get any system support beyond the usual template magic.)
So site types (blogs, wikis, journals, forums, and so on) are just packages you drop on to your main site; each such function is represented by a folder (or a set of folders). The type of the site is merely the type of the default folder for the site. Which is the way I implemented it from day one... but not what the design document said.
Throws a small wrench into my already monkeyed implicit containers, and I will need another database change or two. Plus, it adds, let's see, 3449 new template tags. No, that's not right, I forgot the dot-ops. Well, in total, there are now 6878 template tags relating to folder-level operations.
I did mention that they are highly orthogonal, right? Good.
Posted by: Pixy Misa at
11:22 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 183 words, total size 1 kb.
Thursday, February 22
The second most confusing and problematical aspect of Minx is the system of implicit containers.*
I've mentioned before that Minx has multiple hierachies, defined by Sites, Folders, Threads, Posts and Attachments. You can have as many of each as you want, and they can be nested any way you want, and can be intersected and unioned and what not in many strange and wonderful ways.
For a simple example, let's say you want to go to http://ai.mu.nu/blog/post/thats_going_to_need_stitches
The ai.mu.nu part specifies the site; the blog/post part specifies the folder; and the thats_going_to_need_stitches specifies the thread.** Which is all fine and dandy. That thread will likely have a category assigned to it, which is in fact another folder - in this case the "geek" folder - so that it can also be reached at http://ai.mu.nu/blog/geek/thats_going_to_need_stitches (or something like that). And that category, even though it's actually just another folder which is attached to the entry in question, is to your template an implicit secondary immediate parent structure, so it has to be automatically provided as an appropriate set of template tags.
With me so far?
The problem with this is context. My test site just blew up because the inline comments decided that they needed to be paged (so that only the first 20 comments were displayed inline, and for the rest you had to go to the next page); the problem being that because the page itself was a folder context rather than a thread context, the pager data for the comments (which are posts) wasn't set up. The fix was simply to have the comment paging code check first whether the requisite data was set up... which was a good idea in any case.
This just gets more complicated when you consider that certain objects - the Entry object is a good example - combine the aspects of two or more other objects. An Entry is essentially a Thread combined with a Post, but it also provides access to one or more Author objects and optionally a Folder object, and has to automatically create all the contexts involved. And since an Entry is always viewed inside a Folder context anyway, this can get a little fiddly.
For me. For the user, it's supposed to Just Work™.
One of the solutions I've put in place is explicit substructure tags to complement the implicit tags. Example: The [comments] tag creates a list of comments relevant to the current context, which might be a Folder, a User, a Thread, a Post, or possibly something else. It works out the applicable context automatically, prepares the necessary SQL queries, processes the data, and interprets your template for you. Easy-peasy, unless you wanted it to do something different.
So now, in addition to the semi-automatic [comments] tag and the fully-automatic [comments:here] tag, you have a set of tags such as [entry:comments], [user:comments], [folder:comments], [site:comments], and so on.
The problem with this is that there are, at last count, 12 specialised variants of the [sites] tag, 12 variants of [folders], 6 of [threads], 6 of [posts], and currently 9 of [attachments], and every one of them has to have a complete set of explicit substructure (and superstructure!) tags. So my structural tag table is now dynamically rather than statically generated.
The saving grace, or rather the two saving graces, are these: First, the code for this is largely O(1); the whole template engine works on hash tables, so this doesn't slow it down; and second, because all these variants are variants rather than explicit structures in their own right, this is all actually very well organised. The [category] structure is independent of the [folder] structure (and the [section] structure and the [area] structure and the [archive] and [subforum] and [directory] structures and so on...) but the fields in each one are identical. So as long as you know that [category] is a variant of [folder], you're all set.
How I'm going to structure the documentation for this I don't quite know yet.
* The most confusing and problematical aspect of Minx right now is the user interface customisation system. It doesn't give you a life-jacket, just a whole lot of rope. It's not hard to customise it to the point that you're effectively locked out of your own blog. I will be putting a failsafe in there that lets you log in to the maintenance system using the default settings, but that's not there yet...
** Well, in terms of a blog, it specifies the entry, but keep reading.
Posted by: Pixy Misa at
08:24 PM
| Comments (11)
| Add Comment
| Trackbacks (Suck)
Post contains 751 words, total size 5 kb.
10GBase-T.
I probably still have a 10Base-T hub around here somewhere. We've come a long way, baby.
Posted by: Pixy Misa at
11:10 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 27 words, total size 1 kb.
Thursday, February 08
I can't get to my blog. As far as I can tell, the rest of the world can. After a certain amount of digging, it seems that some of the IP addresses on Akane and Nabiki are no longer reachable from Pixy Central, but what tests I can run remotely indicate that the problem is close to my end and nothing to do with the servers.
But what the problem actually is I have no idea. So I'm going to reset the modem.
...
Nope, that's not it. Bah.
...
Okay, I did a ping test from the modem itself, and now everything works. Double bah with extra cream.
Posted by: Pixy Misa at
07:07 PM
| Comments (1)
| Add Comment
| Trackbacks (Suck)
Post contains 113 words, total size 1 kb.
Sunday, February 04
Steven Den Beste doesn't like to recommend Haibane Renmei as the first show for an anime newcomer to watch, in large part because it's too good. Once you've seen it (he says) it's all downhill from there. I don't entirely agree, but the point is well taken.
And I think I just did that to myself in another field.
I've been wandering about the material on offer at MIT's Open Courseware and Berkeley's Webcasts, and the course I decided to start with was MIT's 9.00 Introduction to Psychology.
I just finished listening to it today (except for lecture 10, which is AWOL), and I have to say that I would cheerfully pay for this series if they had it on CD or something. It's that good. Now, part of that is that it's a subject I've always been interested in but didn't think to take when I had the chance, but a lot of it is the presentation. Jeremy Wolfe is a brilliant lecturer, funny and engaging and able to clearly get the point across. You lose a little with the audio lectures because you're not there, but they are nonetheless superb.
I've tried listening to 9.01 Neuroscience and Behaviour, but it's just not the same.
So if you're at all interested in how your mind works, in what makes you you, in a riotous Freudian analysis of Hansel and Gretel and Snow White, I can't recommend this lecture course too strongly. Download it, evict some songs from your iPod, and listen to it on the way to work. Then you can come back here in a few weeks and thank me.
Really. It's that good.
Posted by: Pixy Misa at
09:16 AM
| Comments (4)
| Add Comment
| Trackbacks (Suck)
Post contains 290 words, total size 2 kb.
Saturday, February 03
There's something screwed up with my Windows box. It won't reboot. Most of the time I don't want it to reboot, but when I need it to do so it won't.
Why? Well, it seems that the boot sector is getting corrupted or something. I say "or something", because if I run a fixmbr and a chkdsk in that order, it will boot. If I only run one of those, generally it won't reboot. If I run chkdsk and then fixmbr, it generally won't reboot either.
What I'm not seeing is (a) any file corruption, (b) any viruses or malware, or (c) any system or application crashes.
This is pretty much how the machine died last September: It was working just fine, then I rebooted to complete an update for iTunes, and it never came back. Only in that case the disk was verifiably toast - it barfed on chkdsk and locked up the computer. This time, the disk is fine, the files are fine, it just won't boot.
So every time something (thanks a bunch, Microsoft!) decides that it has to reboot Windows, it takes me an hour-and-a-half of stuffing around with the Windows Recovery Console to get it back.
I need a new computer. ![]()
Posted by: Pixy Misa at
08:37 PM
| Comments (5)
| Add Comment
| Trackbacks (Suck)
Post contains 213 words, total size 1 kb.
Friday, February 02
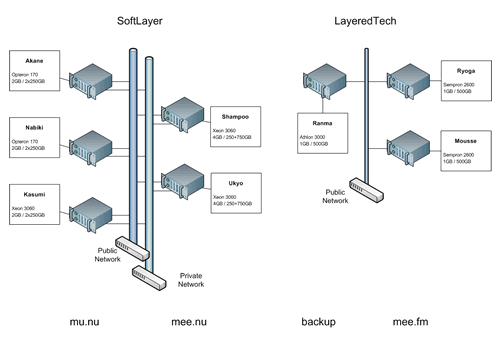
Just waiting for Ryoga and Mousse to come online actually, then the hardware preparations will be complete. And all that will be left to do is... everything else.
Posted by: Pixy Misa at
07:59 PM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 34 words, total size 1 kb.
55 queries taking 0.2 seconds, 389 records returned.
Powered by Minx 1.1.6c-pink.


