






Dear Santa, thank you for the dolls and pencils and the fish. It's Easter now, so I hope I didn't wake you but... honest, it is an emergency. There's a crack in my wall. Aunt Sharon says it's just an ordinary crack, but I know its not cause at night there's voices so... please please can you send someone to fix it? Or a policeman, or...
Back in a moment.
Thank you Santa.
Back in a moment.
Thank you Santa.
Wednesday, January 25
Rough With The Smooth
Rough: InnovaEditor, the standard editor we've been using on mee.nu since the beginning, has been end-of-lifed.
Smooth: It's being replaced by InnovaStudio's new Live Editor, which looks awesome.

Smoother: Existing customers get a free license for the new editor.
Rough: The new editor doesn't come with source code, where the old one did.
Rougher: A source code license is $1099.
Roughest: Which goes up to $1500 after Saturday.
Smoothest: They're already working on the features I need, so I don't need to buy the source code license.
InnovaStudio Live Editor and InnovaStudio tech support get the coveted doesn't suck award. Recommended. Just $70 for an unlimited site single developer license.
Updates after the jump.
more...
Rough: InnovaEditor, the standard editor we've been using on mee.nu since the beginning, has been end-of-lifed.
Smooth: It's being replaced by InnovaStudio's new Live Editor, which looks awesome.
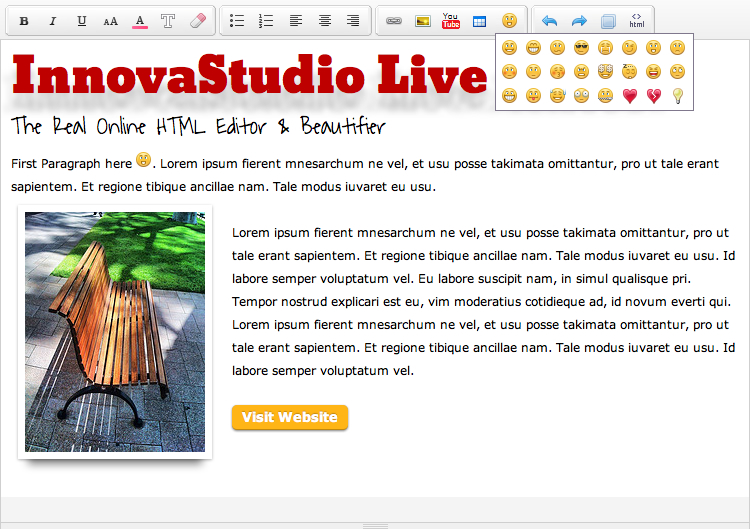
Smoother: Existing customers get a free license for the new editor.
Rough: The new editor doesn't come with source code, where the old one did.
Rougher: A source code license is $1099.
Roughest: Which goes up to $1500 after Saturday.
Smoothest: They're already working on the features I need, so I don't need to buy the source code license.
InnovaStudio Live Editor and InnovaStudio tech support get the coveted doesn't suck award. Recommended. Just $70 for an unlimited site single developer license.
Updates after the jump.
more...
Posted by: Pixy Misa at
10:16 AM
| Comments (5)
| Add Comment
| Trackbacks (Suck)
Post contains 436 words, total size 3 kb.
Sunday, January 22
Indexes Indexes Everywhere
Oh yes, other thing: MongoDB has indexes. And while they're not quite as flexible as CouchDB (which lets you do anything that can be produced by an idempotent function on the record) or Riak (which lets you do anything at all, consistent or not), MongoDB can do what I need, which is building an ordered compound index where one of the components is the elements of an array.

No.
MySQL can't do that (it doesn't have arrays, to start with). PostgreSQL can't do that (it has arrays, and can index them, but can't build an ordered compound index where one component is an array). CouchDB has no problem; Riak will do anything you like; MongoDB can do it, but you can't have two arrays in the index (which would be nice to have available, but isn't going to kill me).
The other database that I know can do it - and might be suitable for Minx - is OrientDB. I'd like to take a look at that too.
But MongoDB, now that those issues have been fixed, is fast enough, flexible enough, and scalable enough. Might not be perfect, but what is?*
* Well, Kimi ni Todoke, but apart from that?
Oh yes, other thing: MongoDB has indexes. And while they're not quite as flexible as CouchDB (which lets you do anything that can be produced by an idempotent function on the record) or Riak (which lets you do anything at all, consistent or not), MongoDB can do what I need, which is building an ordered compound index where one of the components is the elements of an array.

MySQL can't do that (it doesn't have arrays, to start with). PostgreSQL can't do that (it has arrays, and can index them, but can't build an ordered compound index where one component is an array). CouchDB has no problem; Riak will do anything you like; MongoDB can do it, but you can't have two arrays in the index (which would be nice to have available, but isn't going to kill me).
The other database that I know can do it - and might be suitable for Minx - is OrientDB. I'd like to take a look at that too.
But MongoDB, now that those issues have been fixed, is fast enough, flexible enough, and scalable enough. Might not be perfect, but what is?*
* Well, Kimi ni Todoke, but apart from that?
Posted by: Pixy Misa at
11:46 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 204 words, total size 1 kb.
Mongo Revisited
When I first met MongoDB, I was unimpressed, because in my testing it very quickly died and lost all my data. The proximate cause for this was that I was running it under OpenVZ, which will switfly kill any process that runs out of memory (which Mongo did). The reason MongoDB ran out of memory is that...
Well, it didn't, not really; MongoDB works by memory-mapping the entire database and treating it as a persistent data structure, relying on the operating system to provide the persistence layer. One problem with that is that an inopportune event at an inopportune moment can leave you with a pile of unreadable crap where your database used to be. And another problem is that OpenVZ treated it as having run out of memory and killed it... Which meant that on my test bench server - which runs OpenVZ precisely so that I can test things - MongoDB could be consistently made to crash and corrupt itself on small but realistic workloads.

MongoDB standalone. What's the worst that could happen?
Contrast that with CouchDB, the Redis AOF, or Riak's Bitcask, which are all append-only and pretty much bullet-proof: If the entire server crashes before it can write a record, well, you lost that record. But short of going in manually and deleting files, that's the worst that can happen.
So the problem I had was that while MongoDB had the closest semantic fit of all databases I'd seen to what I was trying to achieve with Minx, handing your data to it was like handing your collection of Wedgwood china to an inebriated juggling troupe - it's only a question of when. You could replicate, but then you'd have to make damned sure that the same problem didn't happen to both copies. And running it on OpenVZ was like handing your collection of Wedgwood china to an inebriated juggling troupe - and then setting your house on fire.

MongoDB replicated. All your eggs in two (four?) identical baskets?
MongoDB now has (has for two releases, actually) a journalling facility that will replay lost writes after a power/hardware/software failure. On the whole I'd rather have a persistence mechanism that was inherently safe than an unsafe mechanism with a bungee cord attached for when it inevitably runs into trouble. But while diving off a perfectly serviceable bridge never struck me as a particularly bright idea in the first place, diving off a bridge while firmly attached to it with a bungee cord is rather less likely to end in tears and crocodiles.
Still, if you wanted to run MongoDB, you needed either full-stack virtualisation, a ton of memory, or a dedicated server. For me, the obvious solution is to add a ton of memory and leave the rest of the architecture intact. The problem with being hosted at SoftLayer is that while they offer great support and a great network, their pricing is not so great, and their memory pricing is abominable; a ton of memory costs about three tons of money.*
Apparently that's also now been fixed from the other end: The latest versions of OpenVZ (based on the Red Hat Enterprise Linux 6 branch) bring with them a feature labeled VSwap (virtual swap), which both simplifies and flexiblises memory management and keeps MongoDB under control without mandating either a fiscal or architectural arrow to the knee.

Hurrah! MongoDB and OpenVZ!
But our current server is running on RHEL 5 - actually, I think it's CentOS 5, but basically the same thing - so that requires a reinstall. And if we're going to do that, we'd want to build a new server, test it, and swap over once it's all working. And if we're going to do that, we'd be best advised to wait for a hardware refresh, which didn't happen at all for mid-range Intel servers in 2011, and still won't happen for another couple of months.
Which means... I'll play around with MongoDB a bit more, I think.
* I'm looking into alternatives if they don't smarten up their game, and quickly.
When I first met MongoDB, I was unimpressed, because in my testing it very quickly died and lost all my data. The proximate cause for this was that I was running it under OpenVZ, which will switfly kill any process that runs out of memory (which Mongo did). The reason MongoDB ran out of memory is that...
Well, it didn't, not really; MongoDB works by memory-mapping the entire database and treating it as a persistent data structure, relying on the operating system to provide the persistence layer. One problem with that is that an inopportune event at an inopportune moment can leave you with a pile of unreadable crap where your database used to be. And another problem is that OpenVZ treated it as having run out of memory and killed it... Which meant that on my test bench server - which runs OpenVZ precisely so that I can test things - MongoDB could be consistently made to crash and corrupt itself on small but realistic workloads.

Contrast that with CouchDB, the Redis AOF, or Riak's Bitcask, which are all append-only and pretty much bullet-proof: If the entire server crashes before it can write a record, well, you lost that record. But short of going in manually and deleting files, that's the worst that can happen.
So the problem I had was that while MongoDB had the closest semantic fit of all databases I'd seen to what I was trying to achieve with Minx, handing your data to it was like handing your collection of Wedgwood china to an inebriated juggling troupe - it's only a question of when. You could replicate, but then you'd have to make damned sure that the same problem didn't happen to both copies. And running it on OpenVZ was like handing your collection of Wedgwood china to an inebriated juggling troupe - and then setting your house on fire.

MongoDB now has (has for two releases, actually) a journalling facility that will replay lost writes after a power/hardware/software failure. On the whole I'd rather have a persistence mechanism that was inherently safe than an unsafe mechanism with a bungee cord attached for when it inevitably runs into trouble. But while diving off a perfectly serviceable bridge never struck me as a particularly bright idea in the first place, diving off a bridge while firmly attached to it with a bungee cord is rather less likely to end in tears and crocodiles.
Still, if you wanted to run MongoDB, you needed either full-stack virtualisation, a ton of memory, or a dedicated server. For me, the obvious solution is to add a ton of memory and leave the rest of the architecture intact. The problem with being hosted at SoftLayer is that while they offer great support and a great network, their pricing is not so great, and their memory pricing is abominable; a ton of memory costs about three tons of money.*
Apparently that's also now been fixed from the other end: The latest versions of OpenVZ (based on the Red Hat Enterprise Linux 6 branch) bring with them a feature labeled VSwap (virtual swap), which both simplifies and flexiblises memory management and keeps MongoDB under control without mandating either a fiscal or architectural arrow to the knee.
But our current server is running on RHEL 5 - actually, I think it's CentOS 5, but basically the same thing - so that requires a reinstall. And if we're going to do that, we'd want to build a new server, test it, and swap over once it's all working. And if we're going to do that, we'd be best advised to wait for a hardware refresh, which didn't happen at all for mid-range Intel servers in 2011, and still won't happen for another couple of months.
Which means... I'll play around with MongoDB a bit more, I think.
* I'm looking into alternatives if they don't smarten up their game, and quickly.
Posted by: Pixy Misa at
05:32 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 680 words, total size 5 kb.
Monday, January 16
CouchDB, Riak, And Whatever-The-Hell-You-Want Indexes
One of the things I like most about CouchDB is its index definition mechanism: Javascript.* For each index you want to attach to a database, you write a short Javascript function that assembles the key (or keys) from the fields in the record. CouchDB then manages the underlying B-Tree based on those key values.
This means that if you want to index an array, or a user-defined data structure, or build a partial index, or a full-text index, or anything that can be implemented on top of a B-Tree, you can do it. Write the code once and CouchDB will ensure that it's applied consistently. Far more powerful than standard SQL indexes, and much cleaner and more efficient than using secondary tables, joins, and stored procedures, which are the canonical way to tackle this problem with SQL.
As of version 1.0, Riak supports indexes as well as the basic key/value access and link walking. The way Riak handles things is slightly different to CouchDB.
In CouchDB, each record is a JSON document. Since that's predefined, CouchDB can allow you to inspect the contents of the records and manipulate them using an embedded Javascript interpreter.
In Riak, records are arbitrary binary-safe blobs; you can store anything you want without having to encode it in any special way. To index your records, you provide the index names and values along with the record.
Just like CouchDB, this allows you to build indexes in any way you like. Riak stores the index values twice, once in the index structure and once as metadata alongside the record, so that it can maintain index consistency on updates and deletes without you having to worry about it.
You can have as many indexes as you like (the developers note that they've tested it with 1000 indexes), and like CouchDB, you can do anything you can do with a B-Tree (or rather, with an arbitrary number of B-Trees).
It's a very powerful feature.
* Lua would be better, of course.
One of the things I like most about CouchDB is its index definition mechanism: Javascript.* For each index you want to attach to a database, you write a short Javascript function that assembles the key (or keys) from the fields in the record. CouchDB then manages the underlying B-Tree based on those key values.
This means that if you want to index an array, or a user-defined data structure, or build a partial index, or a full-text index, or anything that can be implemented on top of a B-Tree, you can do it. Write the code once and CouchDB will ensure that it's applied consistently. Far more powerful than standard SQL indexes, and much cleaner and more efficient than using secondary tables, joins, and stored procedures, which are the canonical way to tackle this problem with SQL.
As of version 1.0, Riak supports indexes as well as the basic key/value access and link walking. The way Riak handles things is slightly different to CouchDB.
In CouchDB, each record is a JSON document. Since that's predefined, CouchDB can allow you to inspect the contents of the records and manipulate them using an embedded Javascript interpreter.
In Riak, records are arbitrary binary-safe blobs; you can store anything you want without having to encode it in any special way. To index your records, you provide the index names and values along with the record.
Just like CouchDB, this allows you to build indexes in any way you like. Riak stores the index values twice, once in the index structure and once as metadata alongside the record, so that it can maintain index consistency on updates and deletes without you having to worry about it.
You can have as many indexes as you like (the developers note that they've tested it with 1000 indexes), and like CouchDB, you can do anything you can do with a B-Tree (or rather, with an arbitrary number of B-Trees).
It's a very powerful feature.
* Lua would be better, of course.
Posted by: Pixy Misa at
01:35 AM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 338 words, total size 2 kb.
<< Page 1 of 1 >>
61kb generated in CPU 0.0357, elapsed 0.2426 seconds.
52 queries taking 0.2196 seconds, 367 records returned.
Powered by Minx 1.1.6c-pink.
52 queries taking 0.2196 seconds, 367 records returned.
Powered by Minx 1.1.6c-pink.


