






Ahhhhhh!
Sunday, March 30
Three more BBCode tags on their way to you in next month's update: [search], [filter], and [wiki].
These make it easy for you to refer to related items on your own site. [search=wombat] will provide a link to /search/wombat like this: wombat* That will bring up a search page listing your posts that refer to wombats.
[filter=wombat], on the other hand, produces the link /filter/wombat: wombat* The difference here is that instead of giving you a search page listing the entries, it displays the entries themselves.
Finally, [wiki=wombat] links not to Wikipedia (use [wp=wombat] for that) but to your own lovingly crafted wiki. Or, if you don't have one, to whatever it can find. The link generated is to /wiki/filter.w/wombat: wombat* What this does is an exact title match on items in your wiki folder - or, due to the way Minx works, on your entire site if you don't have a wiki folder.
You can set up a wiki in a number of ways - as a category, as an area (more on those soon), or as a smart folder. And by using a smart folder, you can merge results from any number of other Minx sites, to create your own meta-wiki.
There are some limitations in the 1.2 implementation of smart folders that make it hard to construct a multi-site wiki with clever navigation like you see at TV Tropes, but that will be lifted when I enable cached smart folders, which will be in either a 1.2 update or 1.3.
* Link doesn't work, because we're not on 1.2 yet.
Posted by: Pixy Misa at
01:42 AM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 267 words, total size 2 kb.
Saturday, March 29
A couple of hours of hackery and I've added a very useful new tool to Minx: The [dump] tag.
The dump tag comes in five forms: HTML, XML, HTML table, JSON, and text. What it does is simple: You give it a tag, or a list of tags, and it dumps the tag data in an appropriate format. The one trick is that if you give it the name of an object, it dumps all the fields and sub-fields for you automatically.
This makes it trivial to write, for example, an export routine. This will do it:
[posts count=9999]
<post>
[print.xml post]
[comments]
<comment>
[print.xml comment]
</comment>
[/comments]
</post>
[/posts]Come to think of it, that dump routine would be less than ideal, since it would expand out all the auto-format options. And there are a lot of those.
Want to see just how much data Minx gives you for a single post? Hit the extended entry.
Update: Okay, I've added a [print] tag which strips out most of the excess baggage. So [dump] to get the entire contents of an object, and [print] to get the useful contents.
more...
Posted by: Pixy Misa at
02:26 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 910 words, total size 18 kb.
Friday, March 28
I was overjoyed when EA announced a few years back that SimCity was getting a new release - for about five minutes, until I learned that the new version, dubbed SimCity Societies, represented a marked dumbing-down of the game, focusing on social aspects rather than, well, simulating a city. I fully expected the new game to be a flop, and lo, it came to pass.
The people at EA were apparently worried that the game was becoming too complex to attract new players, and there's some truth to that. Unfortunately, their solution attracted no-one at all. GameSpot gave it a score of 6.0, and in the inflated world of game review scores, that's roughly a 2/10. Not only was it the exact opposite of what I wanted, it wasn't anything anyone else wanted either.
What I want from a city simulator is to be able to choose from commuter rail, light rail, elevated rail, subway, intercity rail, and trams. To be able to pick the designs and layouts of my stations and the stopping patterns of my trains, and how they integrate with my buses and ferries, and to have to send out the emergency crew when a ferry runs backwards down a hill and ends up on the tracks.
I want to have to route not just power and water, but sewer and gas and telephone and cable and fibre and, while we're at it, pneumatic delivery tubes and steam pipes, and deal with the resultant disaster when any two of those networks get cross-connected.
SimCity 4 caused me some grief because my sprawling cities didn't quite fit in my then 512MB of memory... And when I added another 256MB, I tripped over a bug in Windows and my system got corrupted.
But that was then, and this is now. Instead of an Athlon 1.2 with 512MB of memory, I have a dual Athlon 2.6 with 8GB of memory. And if SimCity 5 were actually available, I'd cheerfully upgrade that to a quad-core Phenom. (Which is just a CPU swap.) But, of course, it ain't.
The reason this comes up is that the NSW state government has just announced a new "metro" line for north-west Sydney. The line was announced to run via Wynyard and Epping and then on to Castle Hill and Bella Vista (the suburb that appeared overnight) and beyond.
Which is fine if a little dull. Run the trains from Wynyard over the Harbour Bridge to Chatswood, then through the underground line to Epping (which should open this year), and then up the newly constructed line.
Except that's not what they're doing. What they are doing is rather more interesting, in several ways. This is what the plans are at present:
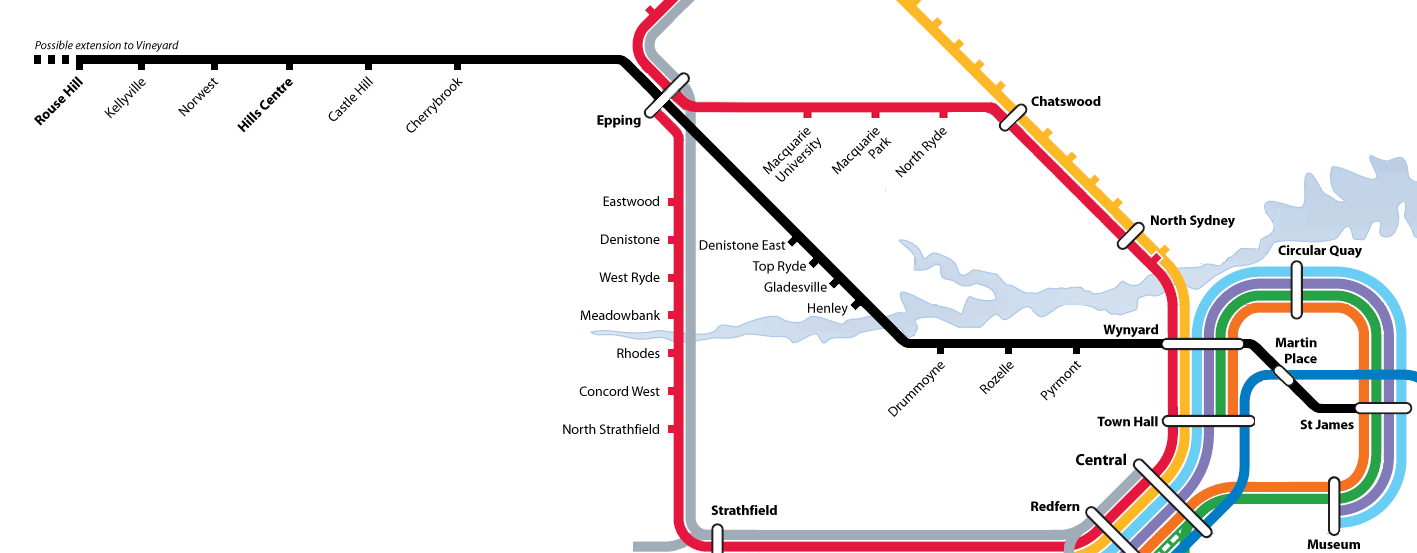
(Click to enlarge. The proposed North West Metro is indicated in black.)
They're starting at St. James, a station I have never had any use for, crossing the city with a stop at Martin Place to Wynyard, then heading due west along the south shore of the Parrammatta River, before making a new crossing, heading up between the North Shore and Northern lines, and creating a third junction point at Epping.
That only leaves two pieces to complete the north-west puzzle - the Carlingford-Epping connection, and the Rouse Hill-Vineyard connection, each of which would tie together two railway lines.
Okay, so they're building a larger and more significant railway than I'd first thought. That's nice, but what, you ask, is so interesting?
Well, there's a lot of history to this, if you know Sydney. For starters, there was a railway line to Castle Hill before. It was never a commercial success, though, and it closed in 1932.
Then there's the oddity of the trains starting at St. James, of all places, probably the least-used of Sydney's underground stations. Why there? This is why:
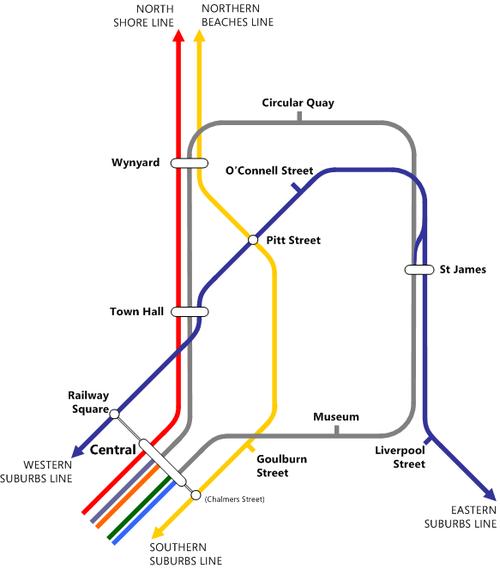
That's part the original plan for Sydney's rail network as envisioned by John Bradfield, who also designed the Sydney Harbour Bridge. The key point here is the blue and yellow lines on that map were never built - at least, not the way they are shown. A short line to the eastern suburbs was built much later via a different route; the northern beaches line remains a wistful thought in the minds of commuters on the packed bendy-buses on Military Road.
But while the lines themselves weren't built, provisions for them were made. On the Sydney Harbour Bridge, which originally had four rail lines and six vehicle lanes, as opposed to the current two and eight; at St. James, which has an odd, single, massively wide platform because it was originally designed to be the junction for the City Circle and Eastern Suburbs lines, and at Wynyard, where the platforms are, curiously, numbered 3, 4, 5 & 6.
So what we get is rather clever. Start from St. James, proceed to Wynyard via Martin Place through tunnels already partly constructed, then turn left and head out past Darling Harbour, possibly sharing right of way with the Metro Light Rail (which was in turn built largely on old goods lines) before heading off to Epping and points north-west.
The plan integrates half of the proposed Anzac Line with the previously proposed North West Rail Link:
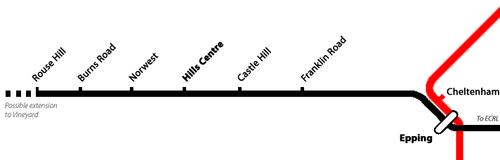
It may even serve part of the purpose of the (proposed, now presumably abandoned) Redfern to Chatswood rail line. If commuters can be delivered the new platforms at Wynyard, Martin Place and St. James, then perhaps Town Hall can get the refurbishment it urgently needs. (They already did what they could without closing at least part of the station, but it's a 1930's-era railway station that serves half the CBD of a major city.)
Once this new line is built, I will have four alternative rail routes to work - assuming, which is unlikely, that I still live and work where I currently do in 2015. See where the red and yellow lines head off the top of the first map? Well, where they join, that's where I live:
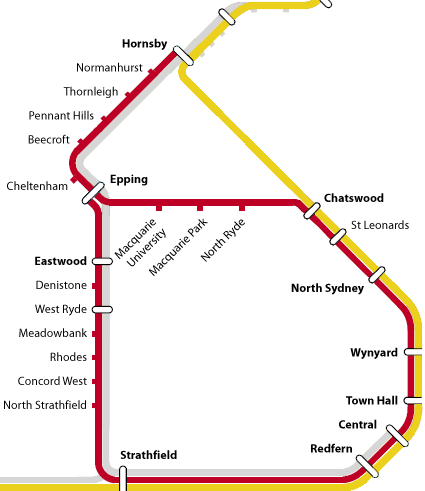
So I'll be able to commute into the city via Chatswood, via Epping, via Epping and then Chatswood (or via Chatswood and then Epping, but then I believe I'd need to change trains), or via Epping and Gladesville.
Oh, and: The adjacent suburbs of North Ryde, West Ryde, and Top Ryde will now all have railway stations - none of which connect directly to the others.
That's what I want to do in SimCity 5. That's the sort of thing that would bring the game to life, that would keep someone (at least, someone like me) tinkering with a city potentially for years. Oh, and pre-ordering expansion packs the moment they are announced.
EA, you've made a
Update: Oh, I forgot to add a mention of this:
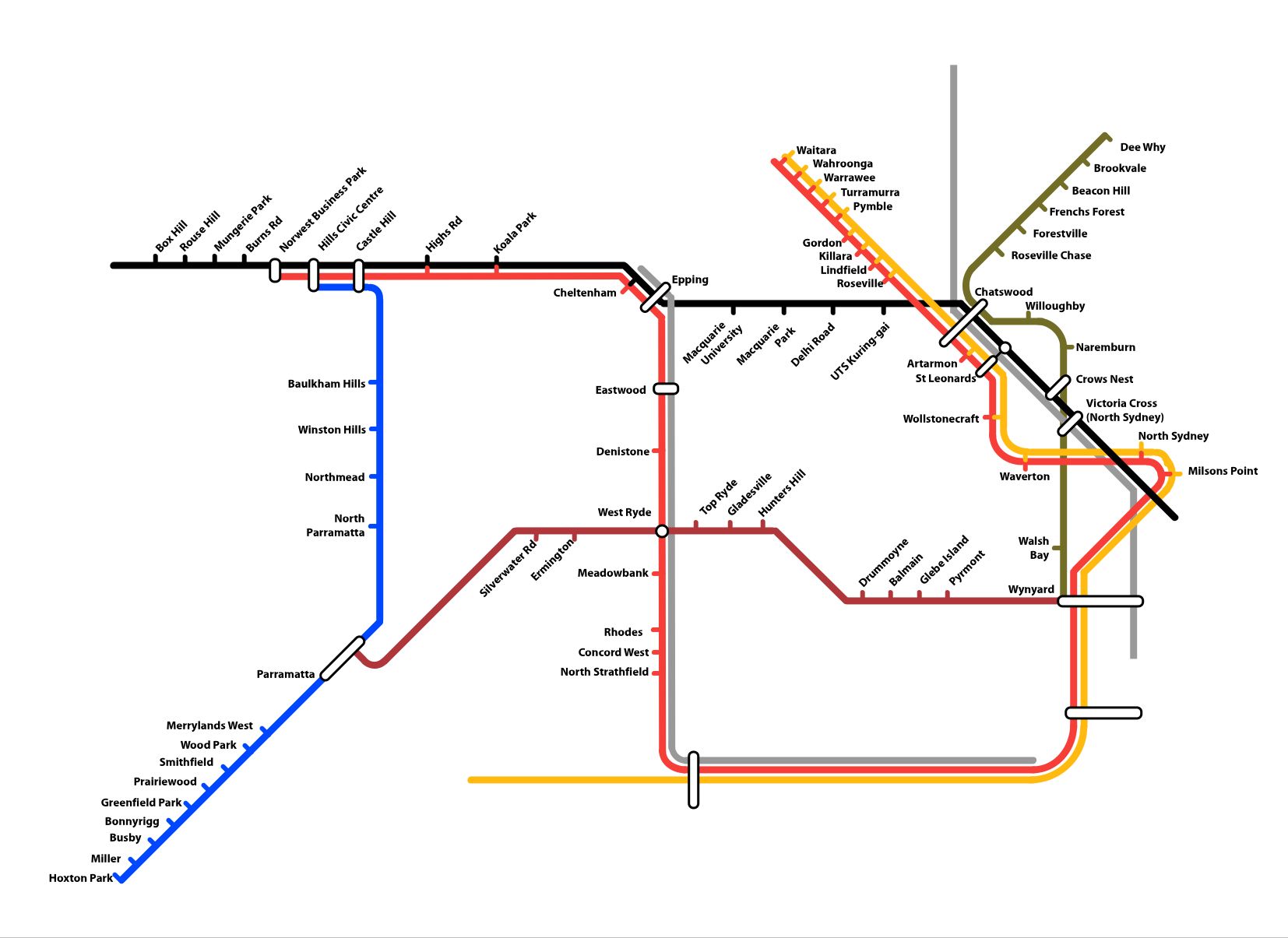
(Click to enlarge.)
That's a wow of a plan if it could be brought off. It's already been superseded in part by the North-West Metro - the Wynard-Gladesville-Epping route on this map is similar, but not the same - but it reconstructs the original Hills Line, and finally builds Bradfield's Northern Beaches Line, at least as far as Dee Why (and via Crows Nest, where I used to live).
It still doesn't connect Carlingford with Epping, though, and considering how close the two are, that's crazy. (If you have a decent sized monitor, Carlingford Station will be at lower left, Epping Station at upper right. A distance of a little over a mile if you dig a tunnel along the route of Carlingford Road, or about 15 miles via the current rail route.)
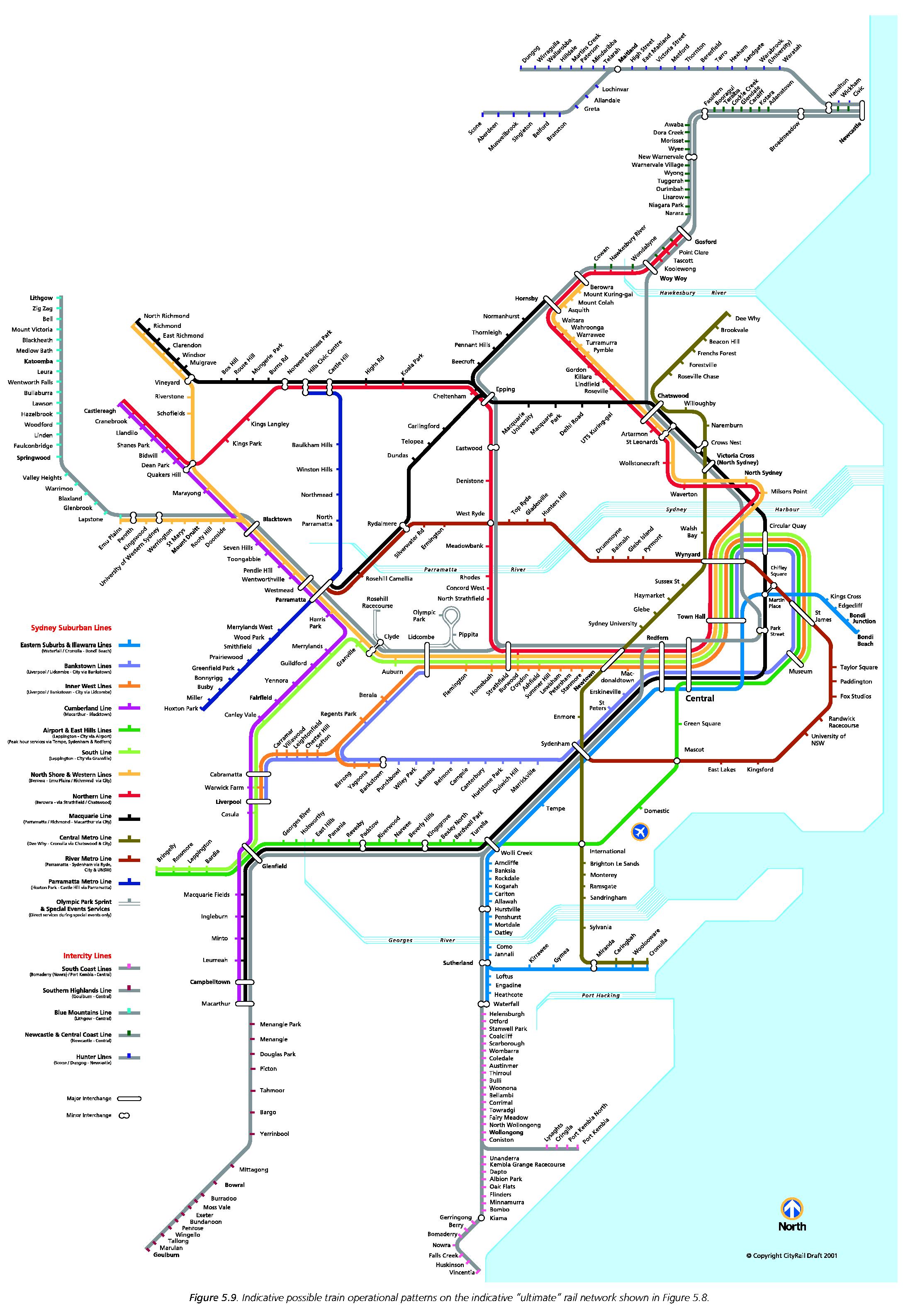
Update: Here's the full plan that the previous map was excerpted from:
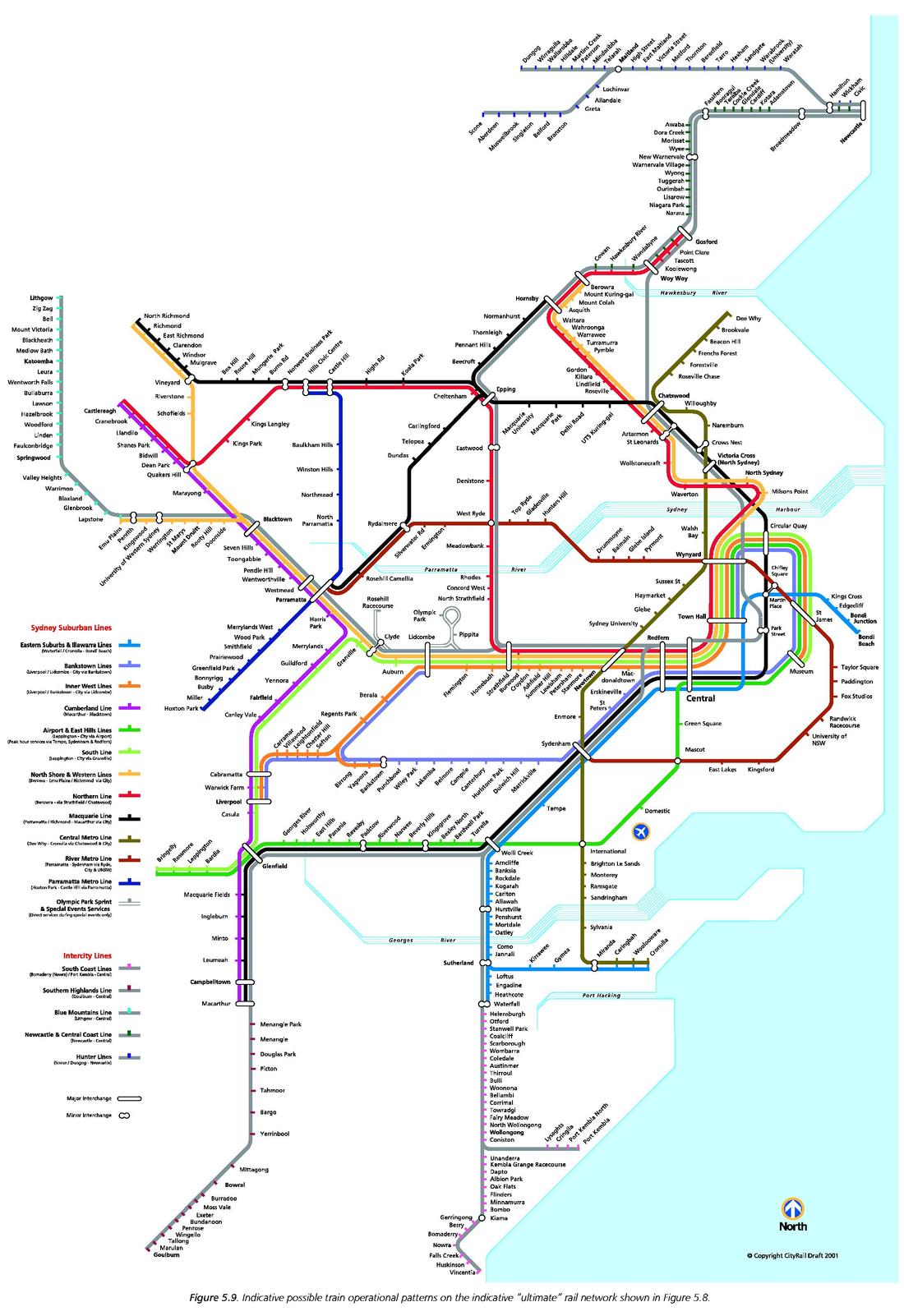
(Click to enlarge.)
The original was at some point resized by an idiot, so the quality isn't great. This is sad, because rail network maps of this complexity are transformed into works of art. I wonder where Wikipedia got their relatively high-quality copy; the only source I could find is here. (Section 5 contains the map.)
Update: Can't find a better copy, so I've resized the original with a soft filter. I also noticed that the full map does have the Carlingford-Epping link. Just needs the Moss Vale-Unanderra line to be reinstated for passenger services, and it's perfect.
Posted by: Pixy Misa at
10:53 PM
| Comments (6)
| Add Comment
| Trackbacks (Suck)
Post contains 1385 words, total size 10 kb.
Saturday, March 22
And there are two likely reasons for that:
- You couldn't; this is a new feature in the forthcoming 1.2 release.
- Um, I never documented it.
- Making sure everything that works is documented.
- Making sure everything that is documented works.
- Moving the support for sites other than blogs from experimental to production.
Progress on the book is slow at the moment because I am testing (and in some cases, coding) the features as I document them. And progress on the 1.2 release has been slowed because I need to document everything as I code. But it's all coming together for a big April release.
In this 25-page excerpt of the book, I give a brief overview of 2 of the top-level tags*, many of the formatting options, and the 1.0-version programming tags.
I think this may take a while.
On the other hand, many of the tags are minor variations on others - there's only about 70 distinct data structures in Minx - so once I get the templates set up I can easily churn out all the different combinations with a bit of cut-and-paste and search-and-replace. Of course, if I overdo that, we'll end up with a 12,000 page manual...
* Out of 1068.
Posted by: Pixy Misa at
10:30 PM
| Comments (6)
| Add Comment
| Trackbacks (Suck)
Post contains 264 words, total size 2 kb.
Tuesday, March 18
Oh, yeah.
The reason the performance issue came up was that I was testing one of the three** methods for sharing posts between blogs. The three being cross-posting (post one entry on two blogs), folder peering (set an entire folder - a category, for example - to appear on two blogs), and direct template hackery.
The last is what I was testing. It works, but with a catch. The old template relied on standard site and folder data to construct the URLs for the permalink and comments pages (which are the same by default, but need not be). That's okay for cross-posting and peering, because the post really is on your site, either at the thread or folder level.
When you engage in template hackery, though, you are calling up posts entirely ad-hoc from another blog (assuming said blog has set access rights to allow you to do so). If we rely on your site data to generate links for posts that only exist on the other site, then those links don't work.
The solution to that is simple - join the folder and site tables in the query and add their public fields to the dataset for the post tag, and modify the templates to use those new fields to construct the links.* But that means a slightly slower query and a little more processing for the tag engine for every page, because while I actually could make the template auto-sense cross-site ad-hockery, it's too much trouble and would scramble the brains of any poor user who just wants to tweak their layout a little.
And so, millisecond by millisecond, performance decreases, and CPUs aren't getting faster at the same rate anymore. The road to Hell is paved not with good intentions, but with "minor" code changes.
* This now works, by the way, though you do need to use the (absolute) post.url tag instead of the (relative) post.path in your templates. Um, once 1.2 is released, that is.
** Four. You can also view friends' and friends-of-friends' posts using template hackery.
*** Five! I just realised that it's dead easy to allow smart folders to work across sites. (Smart folders are much like smart playlists in iTunes - they automatically collect posts from other folders based on whatever search criteria you specify.) The only real work left is setting up the access control.
Posted by: Pixy Misa at
01:40 AM
| Comments (2)
| Add Comment
| Trackbacks (Suck)
Post contains 397 words, total size 2 kb.
I'm preparing for the rollout of Minx 1.2, which has a whole bunch of improvements over 1.1... Speed, on the whole, not being one of them.* I never add anything without optimising it to within an inch of its life, but constantly adding features doesn't come without some cost.
Fortunately Minx is plenty fast for most cases. It can even produce a full page of Ace of Spades with many hundreds of inline comments at a reasonable speed. But I don't like to see those milliseconds slipping away from me.
I've implemented a microcaching system****, and tried it out on the comment sanitiser, which is probably the slowest deterministic function in the system. The results were disappointing, providing only a 10-15% improvement overall. I had thought that the comment sanitiser would have dominated the page generation time, but it turns out not to be the case: If I turn off santisation completely, it's not measurably faster than the cached version.
I need to do another round of profiling, I guess.
In the old days, this could have been resolved simply by swapping the servers for newer and faster ones. Now, though, the fastest servers offered by Softlayer - in terms of single-threaded performance - are only 25% better than what we already have. (And between 50% and 150% more expensive, which is why we have what we have.) I can get 16 cores no problem, but I can't get 4GHz at any price.*****
Intel is coming out with a new CPU architecture this year, codenamed Nehalem. While plenty is known about Nehalem's interconnect architecture (Intel is finally catching up to AMD), not much has been said about the CPU core itself, and even less about its performance.
A presentation recently leaked by Sun (oops) showed Nehalem servers delivering 2.8x the SPECint_rate2006 performance of a 3.0GHz Core2 server. But SPECint_rate2006 is a multi-threaded benchmark, and the details showed that this compares an 8-core dual-threaded system against a 4-core single threaded one, so the single-threaded performance gains could be as little as, well, zero. Rumours since then have put it at between 10% and 25% clock-for-clock. Unless Nehalem also brings a significant clock boost, that's not a lot.
The throughput situation is a lot brighter, but throughput for medium-scale web apps is a solved problem anyway. Multiple cores, multiple CPUs, multiple servers and lots and lots of RAM.
Curse you, laws of physics.
* Except for a few instances like recent comment listings, which were a hack in earlier versions and have been rewritten to use a new folder->post mapping table which provides O(n) performance instead of the previous O(n2 log(n)).**
** Or... Not. Okay, now it takes 2.5 minutes. Back to the query analyser for you, buster!***
*** Ah, there we go. 70 milliseconds worst case. Much better. The whole point of the mapping table was to eliminate the need to sort large sets, so sorting on a field dependent on a join didn't really help.
**** Python provides a remarkably simple and fairly elegant way to do this, using "decorators". Simply by adding the line @qikcache(10000) before a function definition (where qikcache is a caching function I've defined), I change the function to perform a lookup in an LRU cache before carrying out its normal calculations - and to automatically calculate and write the result to the cache if it's not there already.
***** Except from IBM, and the Power6 is a speed-demon design that doesn't deliver signficantly better performance on integer loads anyway. In our case it would be worse, because the Psyco JIT compiler Minx uses only works on x86.
Posted by: Pixy Misa at
01:25 AM
| Comments (6)
| Add Comment
| Trackbacks (Suck)
Post contains 606 words, total size 4 kb.
Monday, March 17
I was fretting just now while in the shower because Midori wasn't exceeding its bandwidth limits this month. Normally I get a daily email after a server reaches 85% of its quota, and this month, nothing.
The problem with that is that if bandwidth is down, page views are down.
But not to worry, Midori is set to hit 2.3TB despite the short month. I just missed the email or something.
Which means $30 in excess usage fees for me. Once that hits $50, it becomes cheaper for me to pay for a virtual private rack and share bandwdith across the servers. (Softlayer's virtual private racks are $25 per server.) Unfortunately I have to commit to that a month in advance, so if we suddenly hit 2.7TB I'll be out twenty bucks. Guess I can deal with that...
Posted by: Pixy Misa at
02:15 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 140 words, total size 1 kb.
Sunday, March 16
It seems that my new server naming scheme of Japanes-girls-names-used-in-anime-that-are-also-colours is feasible after all.
A few months ago we consolidated down from four small servers to two larger ones, Midori and Aoi. But what about the future?
Well, the future is safe, judging by this handy site and this wiki page. Often, the form given is something-iro, meaning something-coloured, but I can live with that.
So I can use Sakura (pale pink), Mikan (a shade of orange), Akari (red), and Momoko (peach). That should keep us going for a while.
Posted by: Pixy Misa at
01:15 PM
| Comments (9)
| Add Comment
| Trackbacks (Suck)
Post contains 92 words, total size 1 kb.
Sunday, March 02
Fractal Wrongness:
The state of being wrong at every conceivable scale of resolution. That is, from a distance, a fractally wrong person's worldview is incorrect; and furthermore, if you zoom in on any small part of that person's worldview, that part is just as wrong as the whole worldview.
Debating with a person who is fractally wrong leads to infinite regress, as every refutation you make of that person's opinions will lead to a rejoinder, full of half-truths, leaps of logic, and outright lies, that requires just as much refutation to debunk as the first one. It is as impossible to convince a fractally wrong person of anything as it is to walk around the edge of the Mandelbrot set in finite time.
If you ever get embroiled in a discussion with a fractally wrong person on the Internet--in mailing lists, newsgroups, or website forums--your best bet is to say your piece once and ignore any replies, thus saving yourself time.
Posted by: Pixy Misa at
10:28 PM
| No Comments
| Add Comment
| Trackbacks (Suck)
Post contains 166 words, total size 1 kb.
55 queries taking 0.1603 seconds, 399 records returned.
Powered by Minx 1.1.6c-pink.



{kind=link}